Nuteo Platform v3.5
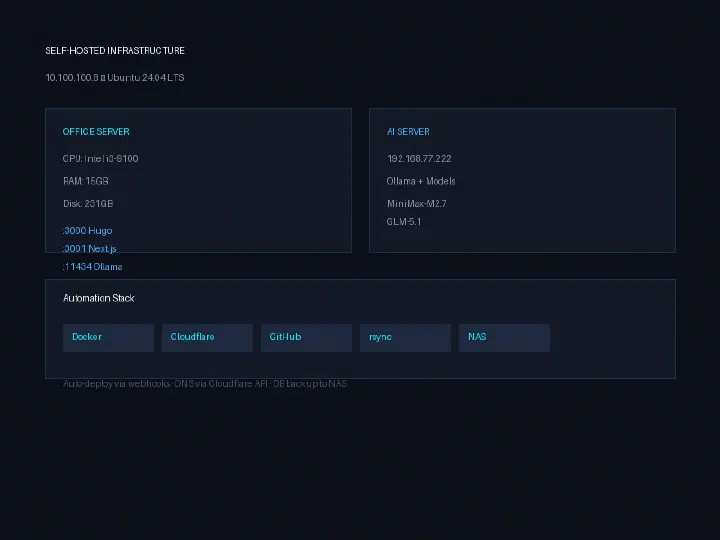
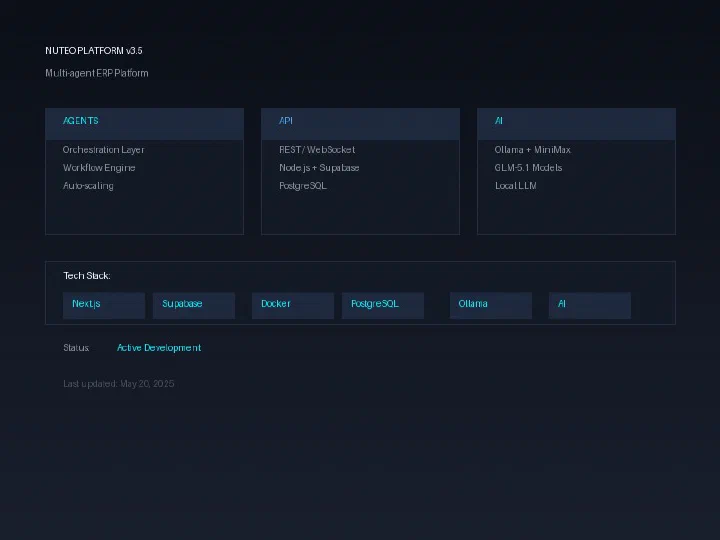
Overview Nuteo Platform 是一款面向现代企业的全栈 ERP 系统。3.5 版带来多智能体编排和自主工作流能力——专为需要不仅仅是任务管理的团队设计。 Tech Stack Frontend: Next.js 16 (App Router, TypeScript, Tailwind) Backend: Node.js APIs + Supabase (self-hosted) AI: Ollama + MiniMax-M2.7 / GLM-5.1 (本地 LLM 编排) Database: PostgreSQL via Supabase Infrastructure: Docker, Ubuntu 24.04, Cloudflare Key Features 多租户 SaaS 架构 实时协作 (WebSocket) AI 驱动的自动化流程 自定义工作流构建器 (拖放) 基于角色的访问控制 API 优先设计 Status 🟢 Active Development — 小团队生产就绪 Stack: Next.js · Supabase · Ollama · Docker